提示工程AI测试与运维

点击查看大图
点击查看大图
点击查看大图
点击查看大图
点击查看大图

点击查看大图
全面介绍
✨ Agenta: 您的开源 AI 团队提示管理与评估利器 ✨
Agenta 是一个强大的开源 LLMOps 平台,专为构建高可靠性 AI 应用而设计。我们致力于帮助开发者与领域专家无缝协作,让您的 LLM 应用发布过程更快速、更自信!
💡 Agenta 如何助您成功?
- 告别混乱: 不再让提示词散落在 Slack、Google 表格或邮件中。Agenta 提供统一的提示管理中心。
- 打破孤岛: 产品经理、开发者和领域专家可以紧密合作,共同迭代。
- 终结“拍脑袋”上线: 彻底告别盲测,告别凭感觉修改并发布到生产环境。
- 效果可视化: 清晰了解每次实验是否真正提升了性能。
- 调试无忧: 当问题出现时,告别猜测,精准定位错误根源。
🎯 Agenta 核心功能概览
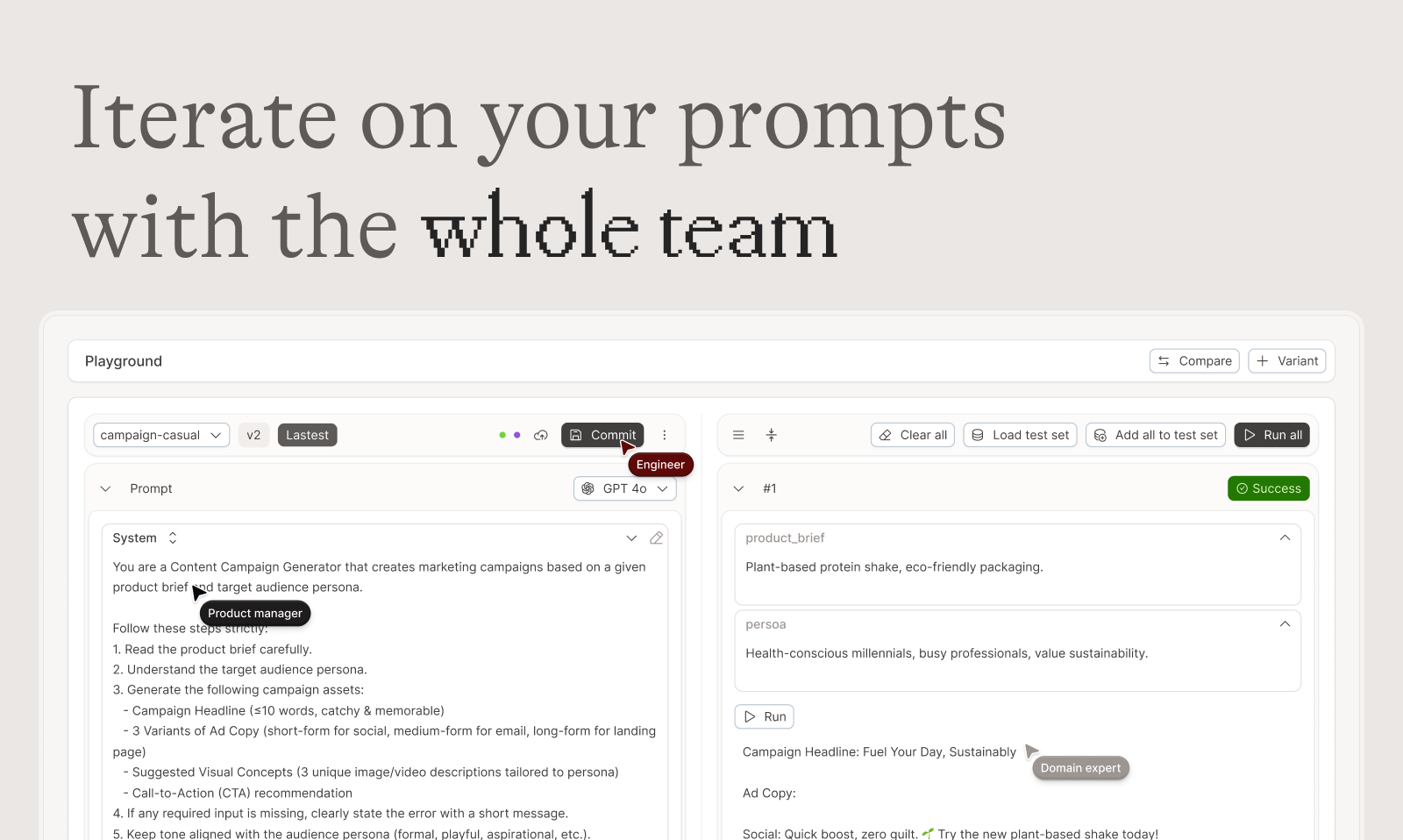
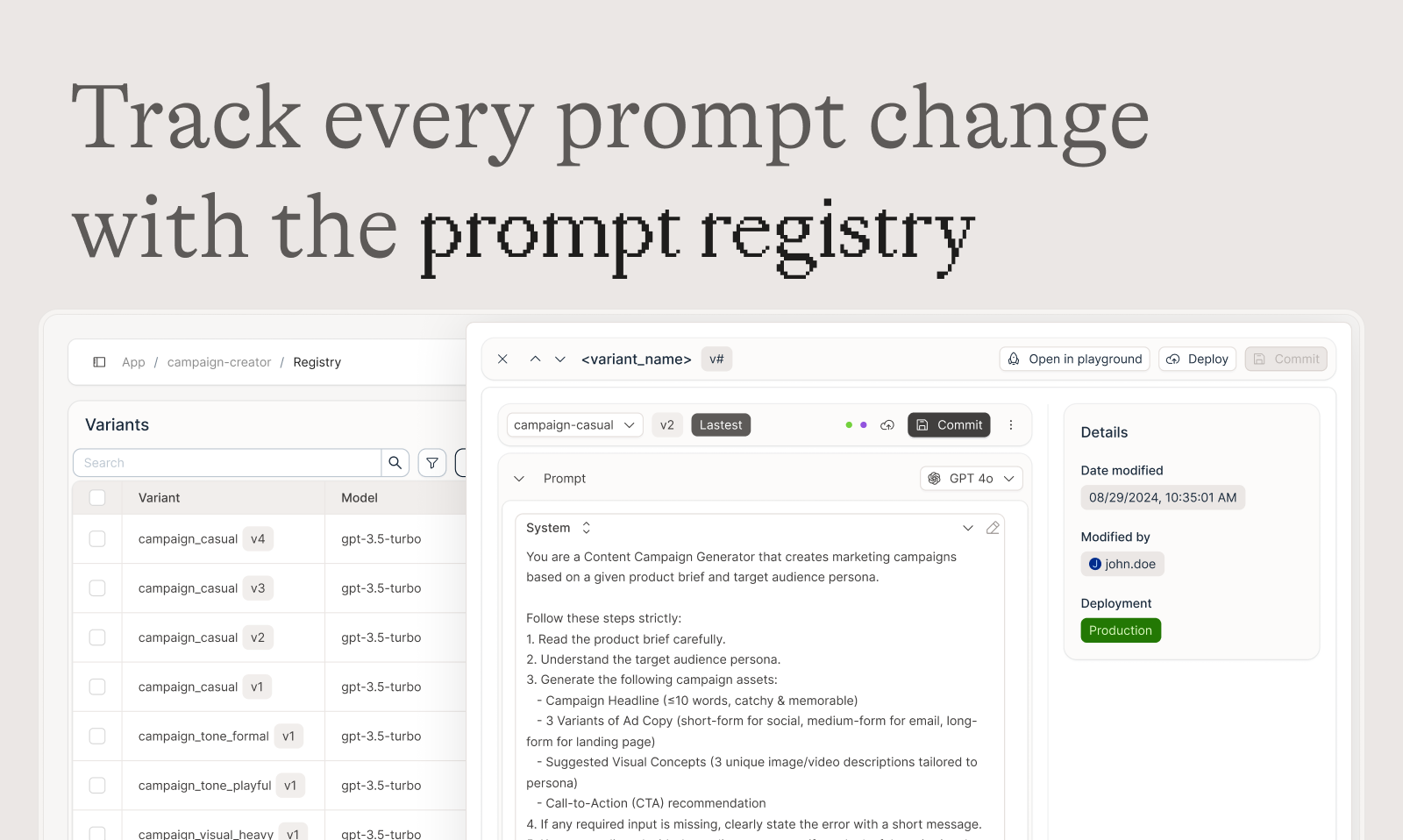
🚀 统一的提示词操作台 (Unified Playground)
“Found an error in production? Save it to a test set and use it in the playground.”
- 并排比较: 同时比较不同提示词和模型的效果。
- 版本历史: 完整的提示词版本控制,轻松追踪每次变更。
- 模型无关性: 灵活支持多种 LLM 模型。
- 即时调试: 在生产环境中发现问题?一键保存为测试用例,并在操作台中进行调试。
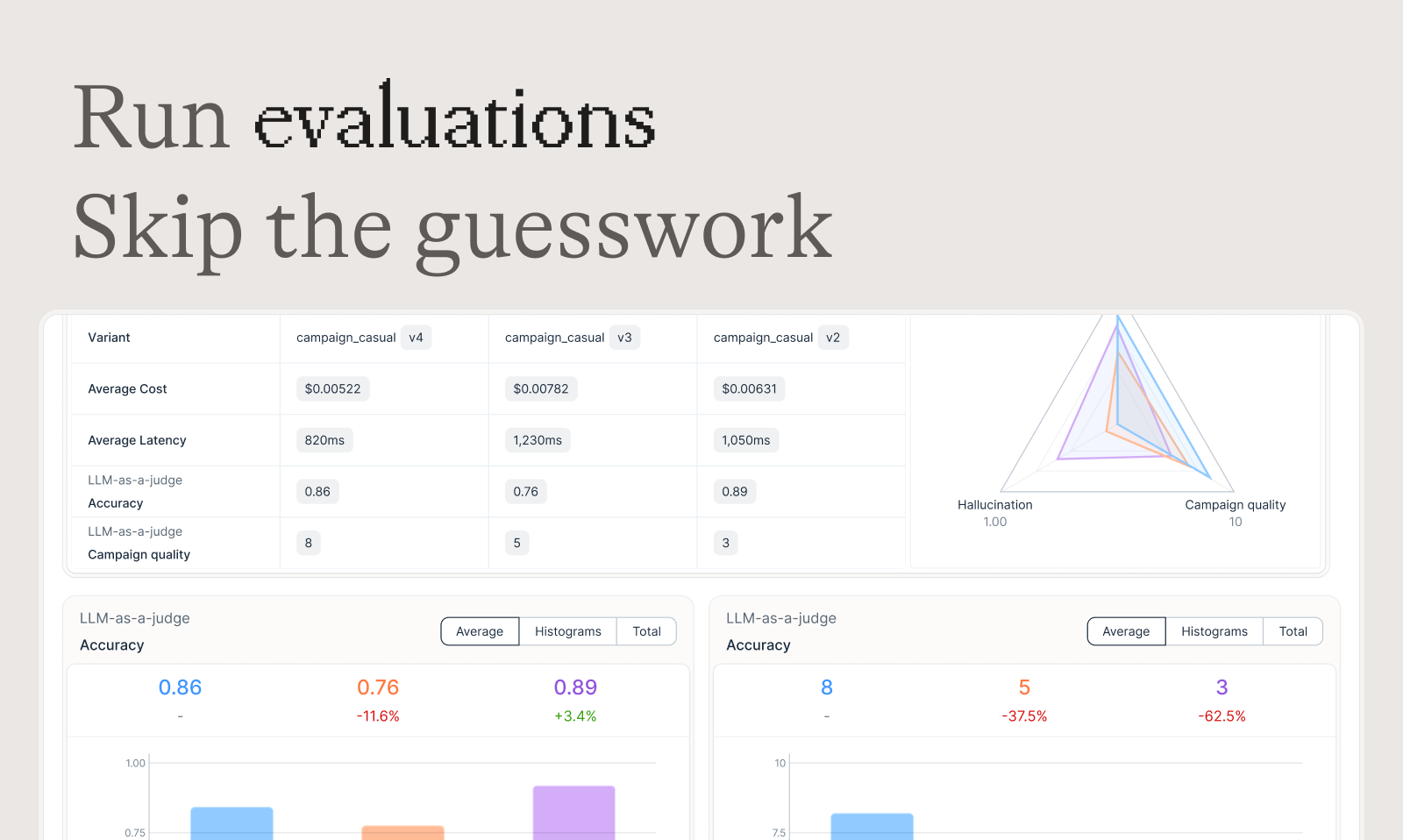
📊 自动化评估 (Automated Evaluation)
建立系统化的流程,运行实验、追踪结果并验证每一次改动,确保您的应用质量。
- 灵活集成: 支持集成各种评估器。
- 完整链路评估: 不仅仅是最终输出,还能比较并测试代理推理过程的每一个中间步骤。
- 人工评估: 将领域专家的宝贵反馈融入评估工作流。
- 在线评估: 实时监控性能,通过在线评估检测回归,防患于未然。
- 可定制的 LLM-as-a-Judge 输出模式: 配置 LLM-as-a-Judge 评估器,支持二元、多分类或自定义 JSON 格式,并通过推理提升评估质量。
- SDK 编程评估: 通过 SDK 以编程方式运行评估,完全控制测试数据和评估逻辑,并在 Agenta 控制面板中查看结果。
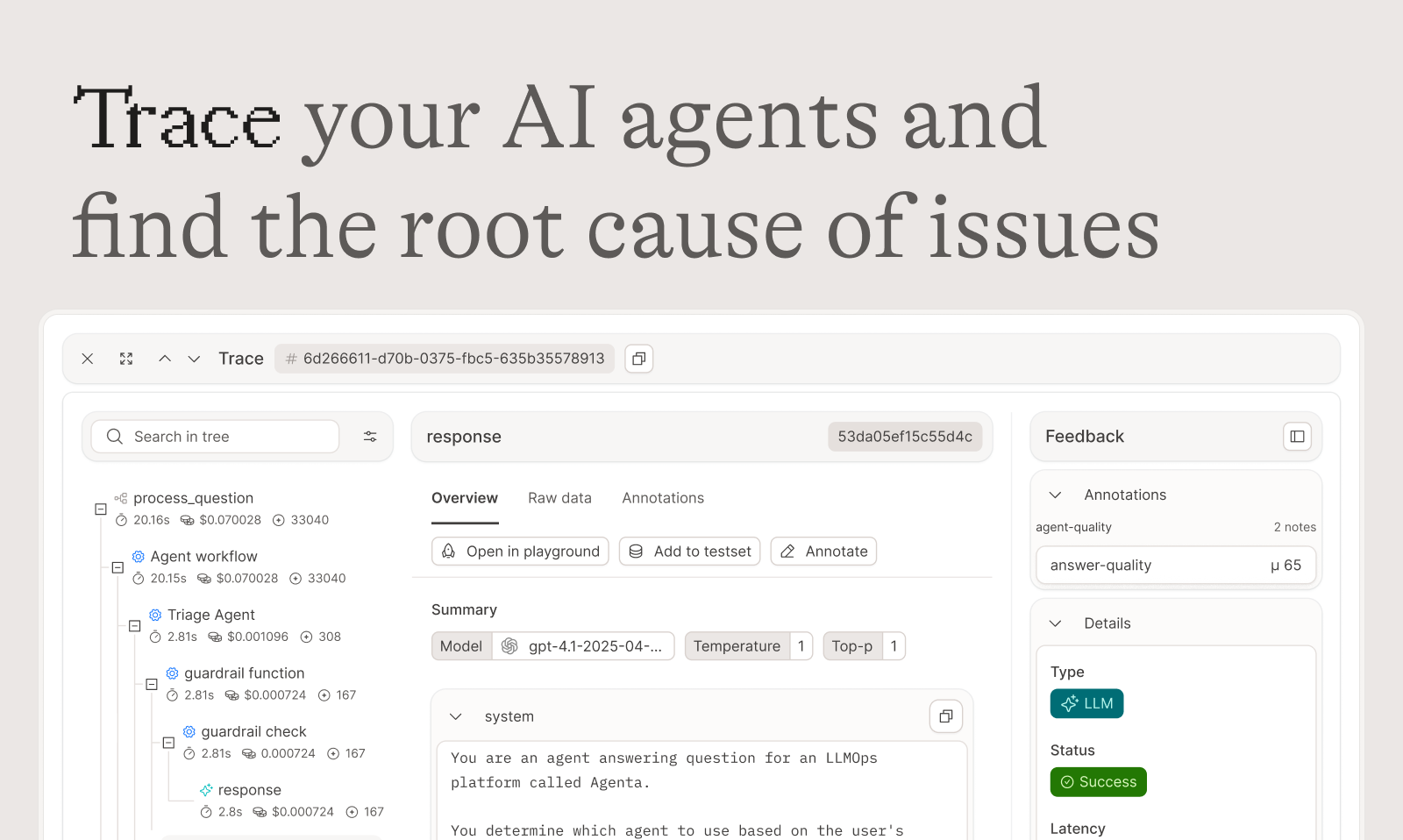
🔍 可观测性 (Observability)
- 追踪每次请求: 准确找出故障点。
- 标注追踪: 与团队协作或获取用户反馈。
- 一键转化为测试用例: 将任何追踪记录转化为测试用例,形成闭环反馈。
- 性能监控: 实时监测应用性能,并在线评估检测潜在的回归问题。
🤝 赋能团队协作
- 专家友好的用户界面: 赋能领域专家安全地编辑和实验提示词,无需编写代码。
- 人人参与评估: 产品经理和专家可以直接通过用户界面运行评估和比较实验。
- API 与 UI 完全同步: 将编程工作流和用户界面工作流整合到一个中心枢纽。
🌱 Agenta 产品路线图亮点 (部分)
🚀 已发布功能
- PDF 支持: 现已在操作台中支持 PDF 文档附件。
- Jinja2 模板支持: 在提示词中使用 Jinja2 模板,增加条件逻辑和过滤器。
- 项目内的组织结构: 在组织内创建项目,将工作按不同的 AI 产品划分。
🛠️ 正在开发中
- 聊天会话视图: 将整个聊天会话整合到一个视图中,方便查看。
- 提示词文件夹组织: 在操作台中创建文件夹和子文件夹,更好地组织提示词。
💡 计划中
- AI 驱动的提示词优化: 在操作台中分析提示词并提出改进建议。
- 直接在操作台中打开可观测性 Span: 从可观测性界面一键在操作台中打开聊天 Span。
🌐 了解更多
- GitHub Star: 深入研究代码,贡献力量,了解为什么成百上千的开发者都为我们的项目点赞!
- 加入社区: 有疑问或想法?欢迎加入我们的 Slack 频道,与数百名 AI 开发者一起交流。
产品评分
暂无评分
登录后即可评分