基础大模型

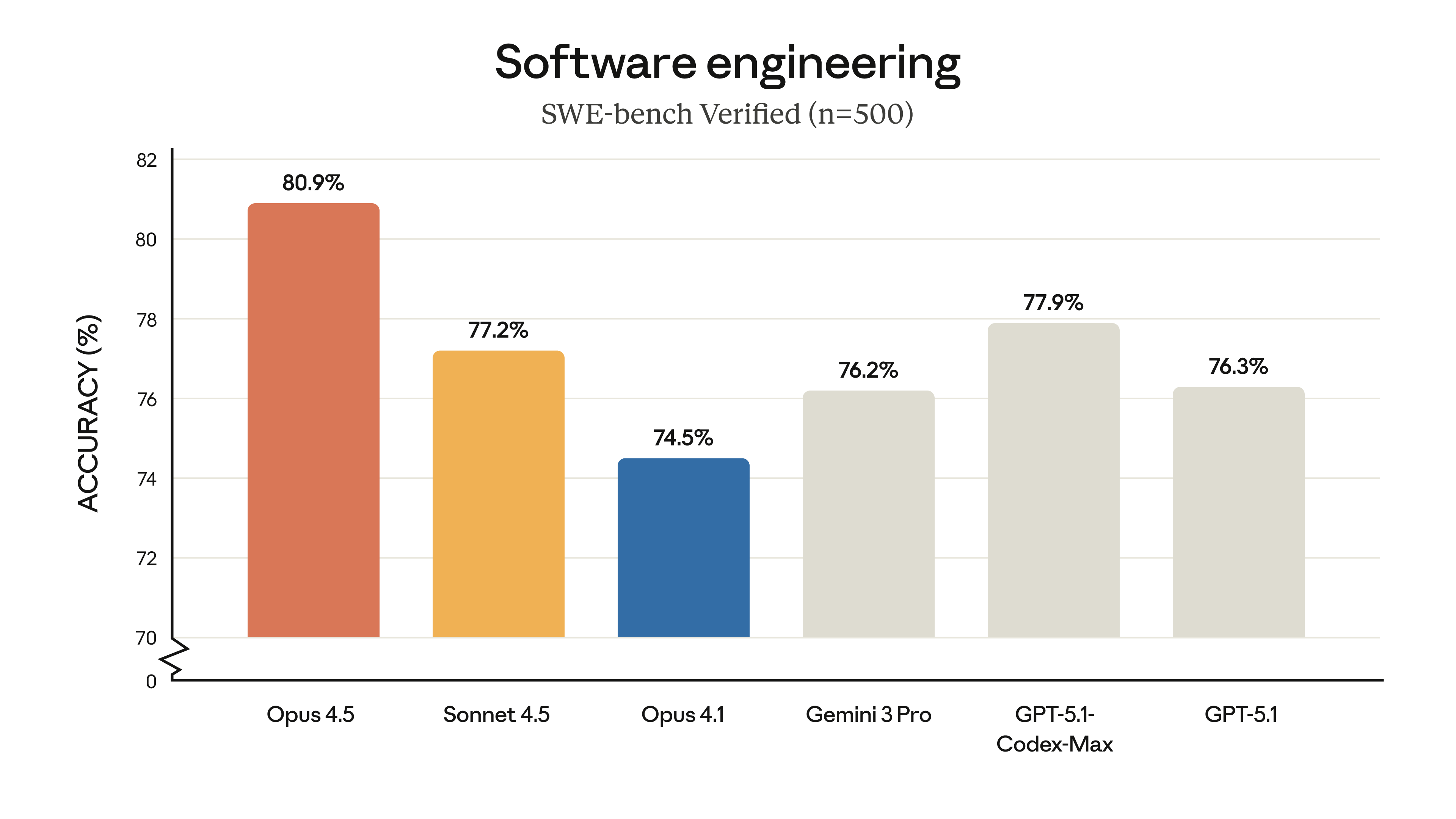
点击查看大图
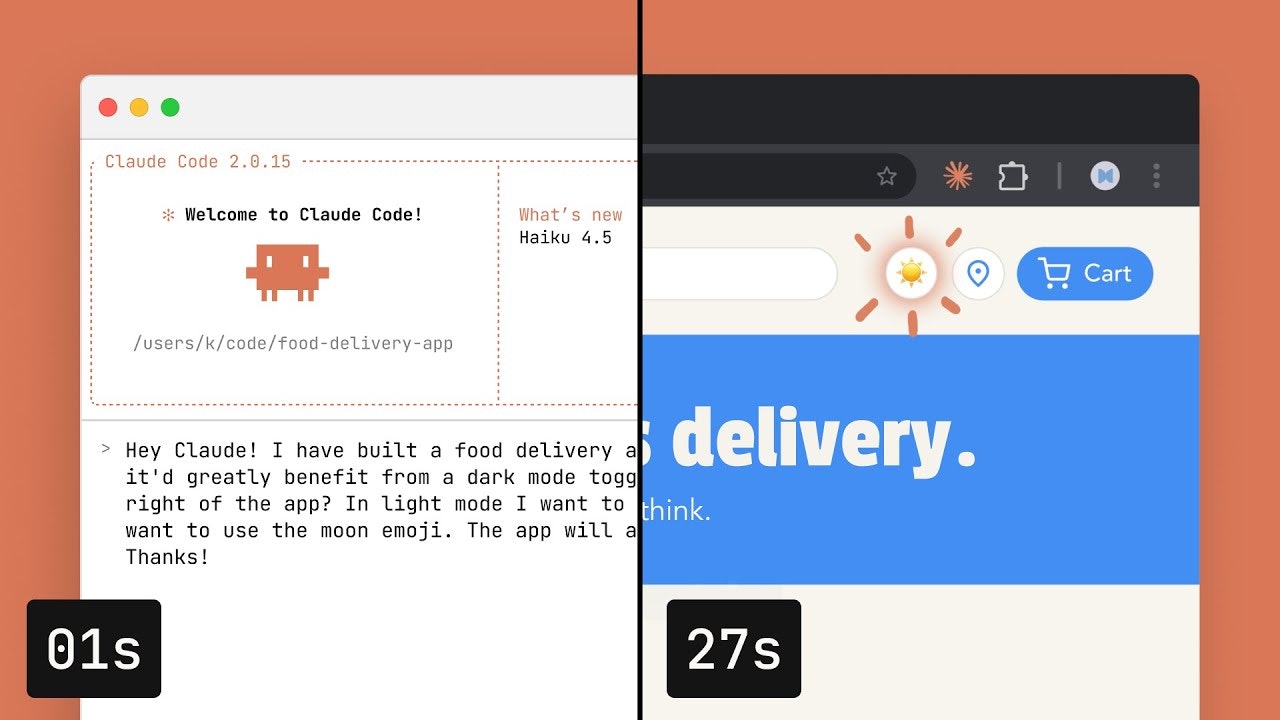
点击查看大图
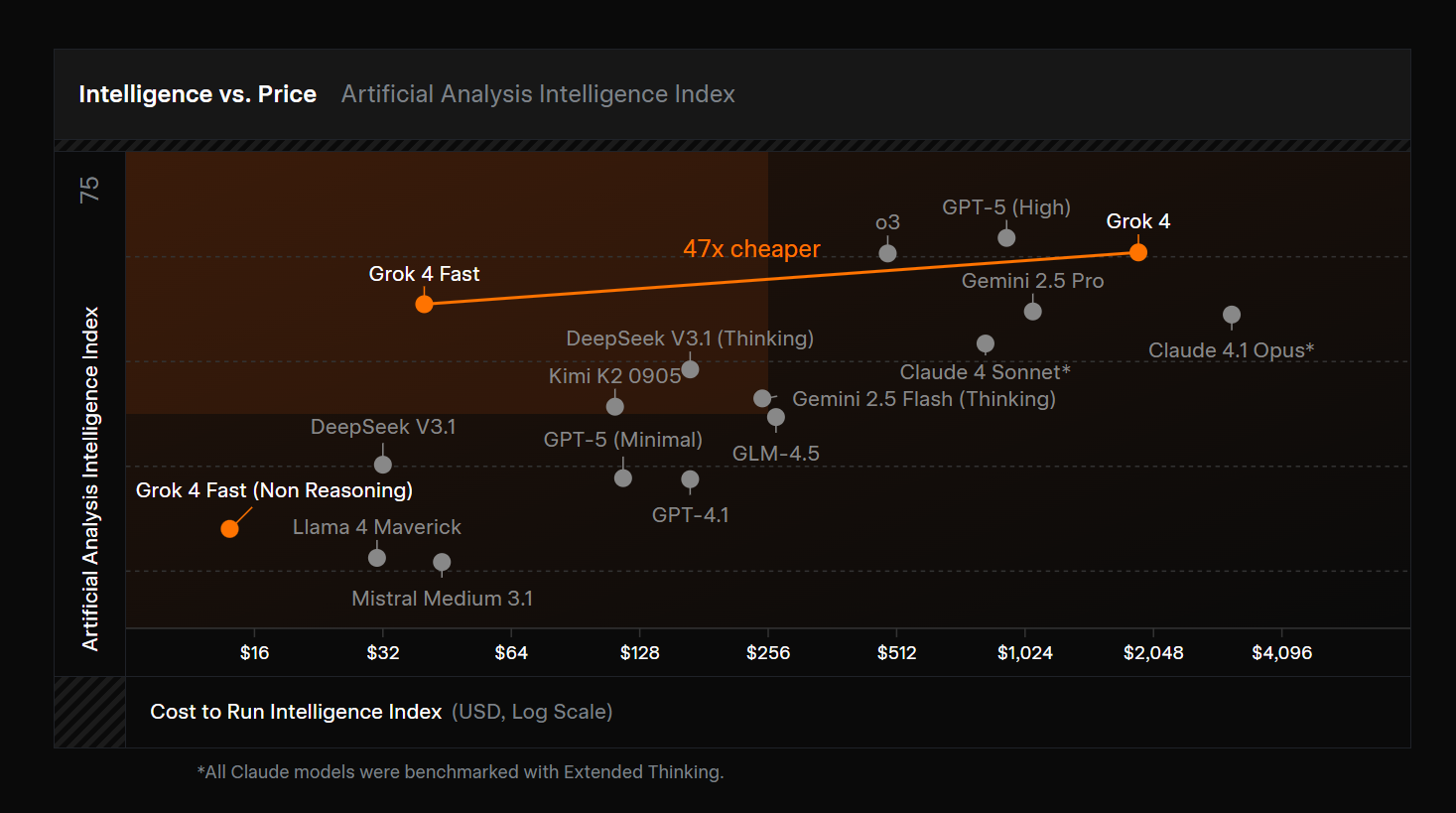
点击查看大图

点击查看大图

点击查看大图
点击查看大图

点击查看大图

点击查看大图
全面介绍
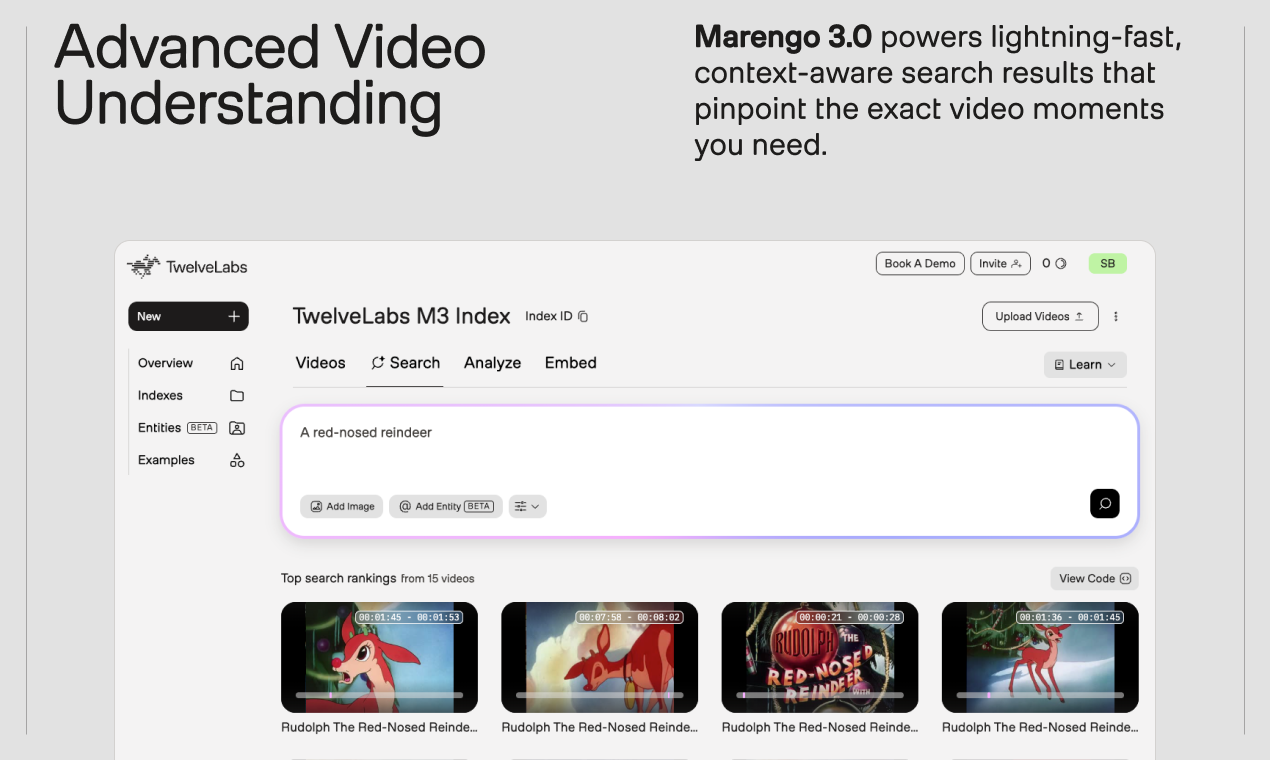
✨ TwelveLabs Marengo 3.0:视频理解新纪元!
隆重推出 TwelveLabs 迄今为止最强大的模型——Marengo 3.0,它将视频理解能力提升至前所未有的高度,实现真正类人级的视频内容洞察。
我们深知,视频时代的信息爆炸让内容检索变得愈发复杂。Marengo 3.0 正是为此而生,旨在帮助您轻松驾驭海量视频数据,精准锁定每一个精彩瞬间。
💡 产品亮点:多模态融合,全面理解视频
Marengo 3.0 是一款先进的多模态嵌入模型,巧妙地融合了视频、音频和文本信息,为您提供:
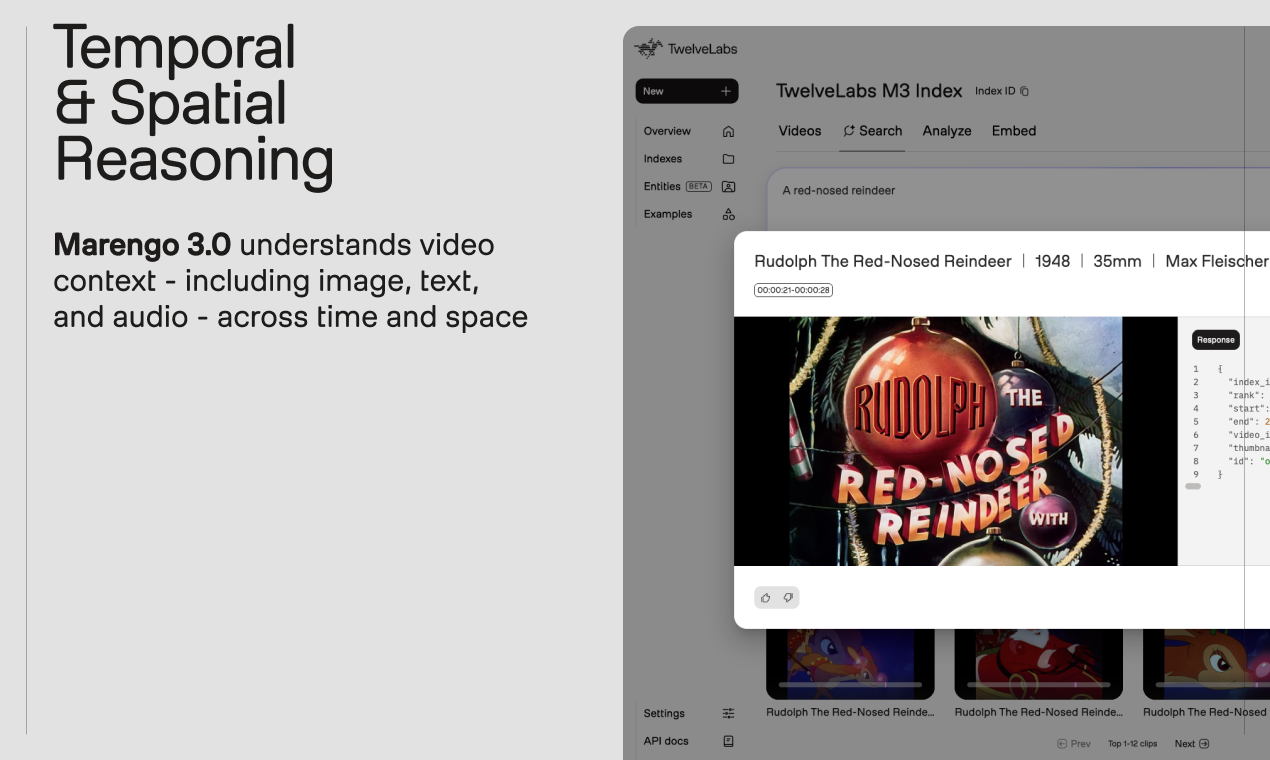
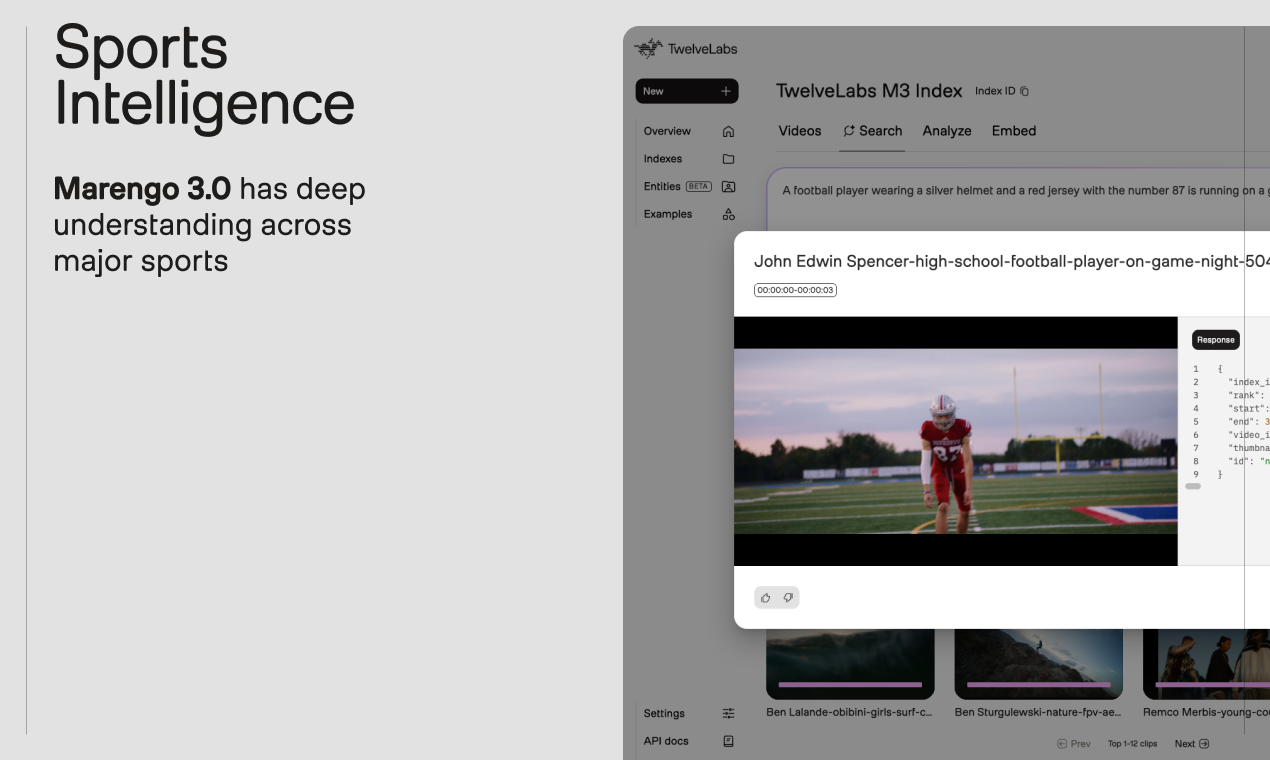
- 🎥 视频内容洞察: 深入理解视频中的视觉元素和时间关系。
- 🔊 音频情感捕捉: 分析语音和声音,捕捉视频的听觉细节。
- ✍️ 文本语义关联: 将视频内容与文本描述无缝连接。
这项强大的融合能力,让 Marengo 3.0 能够以更接近人类认知的方式来“看”、来“听”、来“理解”视频内容,为您的应用提供坚实的基础。
🎯 核心优势:精准搜索与高效检索
有了 Marengo 3.0,您将体验到前所未有的视频搜索和检索能力:
- “任意到任意”搜索: 无论是通过文本、图片、音频还是其他视频片段,都能精确找到您在庞大视频库中的任何目标时刻。告别大海捞针,迎接精准定位!
- 丰富的嵌入表示: Marengo 3.0 可生成高质量的数值表示(embeddings),这些“数字指纹”是构建各种复杂功能的基石,例如:
- 语义搜索: 根据内容的意义进行搜索,而非简单关键词匹配。
- 混合搜索: 结合多种搜索维度,提升检索准确性。
- 异常检测: 快速识别视频中的不寻常事件或行为。
- 以及更多定制化应用……
“Marengo 将文本、音频、图像和视频转化为数值表示,这些被称为嵌入(embeddings)。凭借其‘任意到任意’的搜索能力,您可以轻松在海量视频中 pinpoint 确切的时刻。”
🚀 我们的愿景:改变与革新
在 TwelveLabs,我们致力于从根本上改变人们看待、使用和理解视频的方式。Marengo 3.0 的发布,正是我们这一愿景的生动体现。我们相信,视频原生 AI 将帮助机器更好地理解世界,同时也赋能人类,更好地捕捉、讲述和利用他们的视觉故事。
选择 Marengo 3.0,与我们一同开启视频理解的下一个篇章吧!
产品评分
5.0(1 条评分)
登录后即可评分
5
0.0%
4
0.0%
3
0.0%
2
0.0%
1
0.0%