模型微调与部署模型开发工具

点击查看大图
点击查看大图

点击查看大图
全面介绍
Tinker:您的模型微调利器 ✨
Tinker 是一款灵活高效的 API 工具,专为使用 LoRA 技术微调开源模型而打造。无论您是研究人员还是开发者,Tinker 都能为您提供高度自由的训练体验,让您专注于算法和数据逻辑,无需操心底层运维。轻松掌控流程,定制属于您的模型优化方案。
“Tinker 让我们能够专注于研究,而不是花费时间在工程开销上。这是任何数量的裸 GPU 算力都无法替代的。”
—— Tyler Griggs
💡 Tinker 为何与众不同?
- 掌控一切,简化繁琐: Tinker 提供强大的 API,让您能精细控制模型训练与微调的每个细节,同时将复杂的底层基础设施管理工作交给 Tinker,您只需聚焦核心算法和数据。
- LoRA 技术加持: 我们采用 LoRA (Low-Rank Adaptation) 技术,通过训练一个小型的附加模块而非修改模型所有原始权重,实现高效且精准的模型微调。
- 专注于创新,而非运维: Tinker 旨在让研究人员摆脱繁琐的计算和基础设施复杂性,将精力投入到数据集、算法和实验环境中,加速您的创新进程。
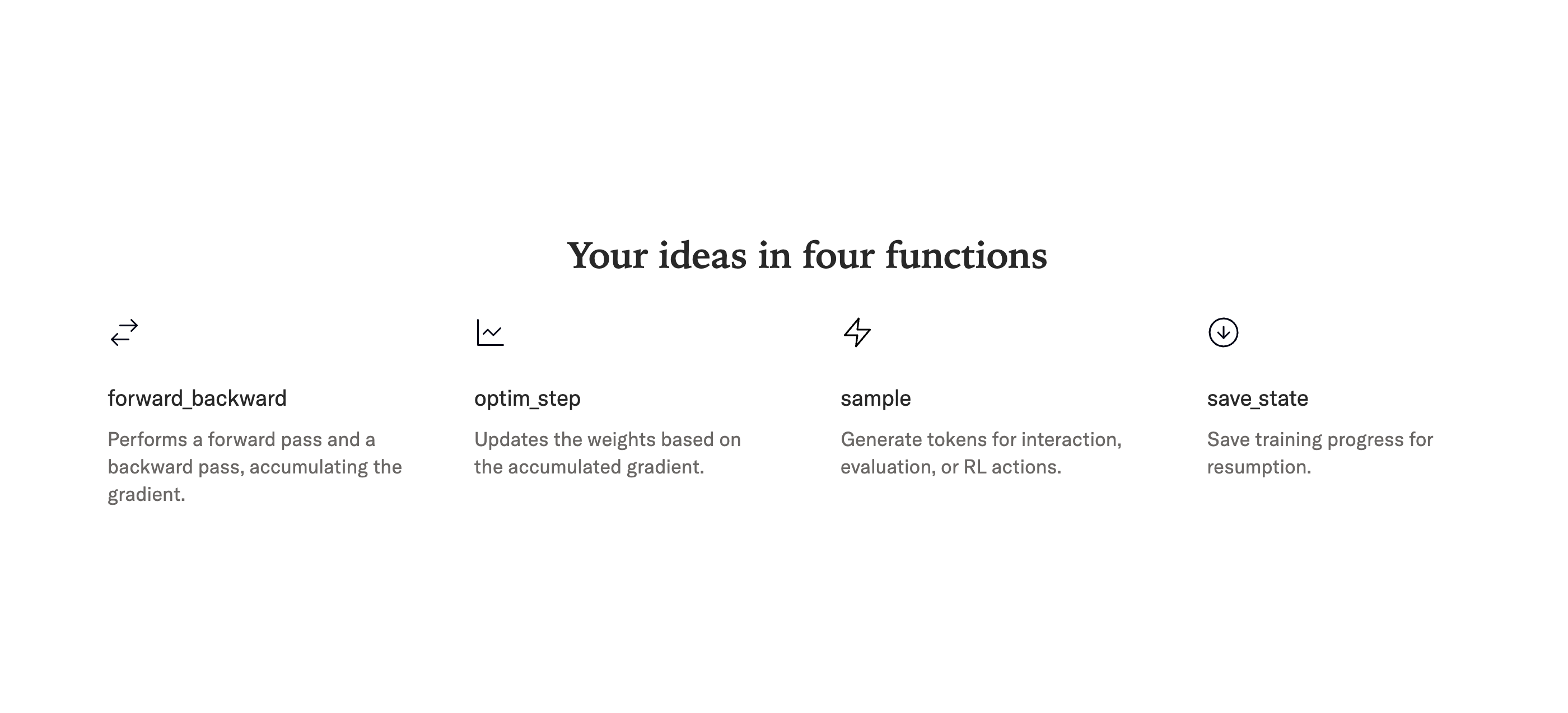
🎯 核心功能一览
Tinker 将您的创新想法浓缩为四个直观的函数:
-
forward_backward:执行前向传播和后向传播,并累积梯度。 -
optim_step:基于累积的梯度更新模型权重。 -
sample:生成 token,用于交互、评估或强化学习操作。 -
save_state:保存训练进度,以便随时恢复。
“Tinker 使我们能够专注于数据和评估,轻松地跳入强化学习工作,因为训练基础设施已经被抽象出来。”
—— Ziran Yang, Yong Lin, Chi Jin
🚀 支持主流模型
Tinker 目前已支持一系列主流开源模型,包括:
- QWEN 系列
- LLAMA 系列
💰 定价信息
Tinker 的定价方案基于计算使用量,所有价格均以美元/每百万 token 计费。
请参考以下定价表,了解不同模型的预填充 (Prefill)、采样 (Sample) 和训练 (Train) 成本:
(注:此处将模拟表格,产品详情页通常会直接嵌入表格图片或更复杂的HTML,但根据要求,我将以纯文本列出部分示例,并提示实际情况。)
部分模型定价示例:
- Qwen3-4B-Instruct-2507: Prefill $0.07, Sample $0.22, Train $0.22
- Qwen3-8B: Prefill $0.13, Sample $0.40, Train $0.40
- Llama-3.2-1B: Prefill $0.03, Sample $0.09, Train $0.09
- Llama-3.1-70B: Prefill $1.05, Sample $3.16, Train $3.16
- ...更多模型的详细定价请见 Tinker 官网定价页面。
“Tinker 一直以来都是可靠的,让我们能够快速迭代而无需担心硬件或基础设施。”
—— Eric Gan
产品评分
暂无评分
登录后即可评分