全面介绍
✨ TuneTrain.ai: 轻松打造您的专属 AI 模型 ✨
无论您是开发者小白还是专业人士,TuneTrain.ai 都能让 AI 模型训练变得触手可及。 我们专注于将复杂的技术化繁为简,让您轻松拥有强大且定制化的语言模型。
💡 产品亮点与核心功能
- 无需编程,轻松上手: 告别繁琐代码,通过直观界面即可完成 AI 模型训练。
- 少量数据,强大模型: 仅需少量示例数据,平台智能自动扩充,打造高质量数据集。
- 定制化语言模型: 训练符合您特定需求的 AI 语言模型,满足各种应用场景。
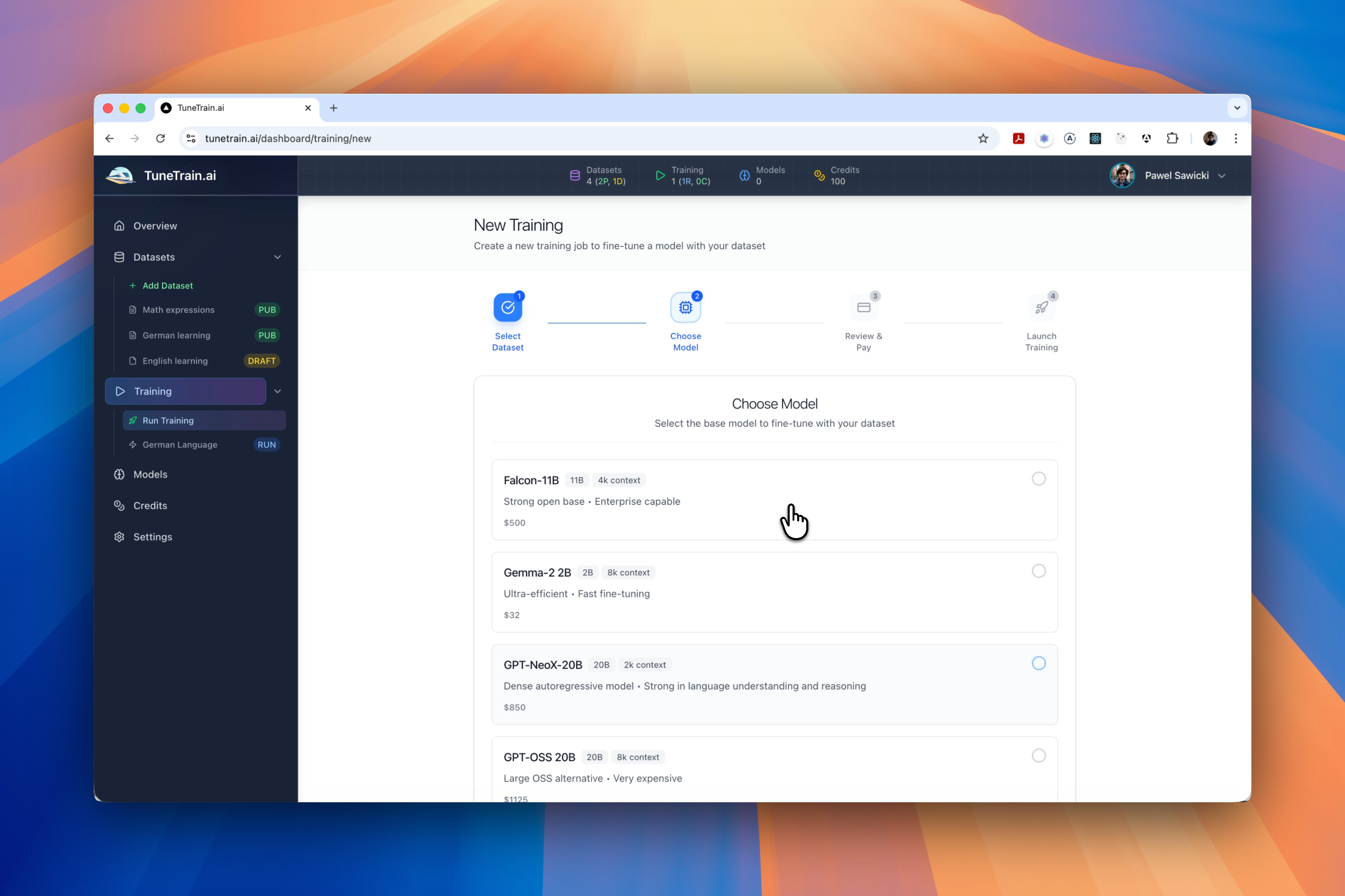
- 主流模型支持: 精心挑选并支持 Llama 3, Mistral, Phi-4, Gemma, Qwen 等领先模型,兼顾效率与性能。
🎯 我们如何帮助您精炼 AI 模型?
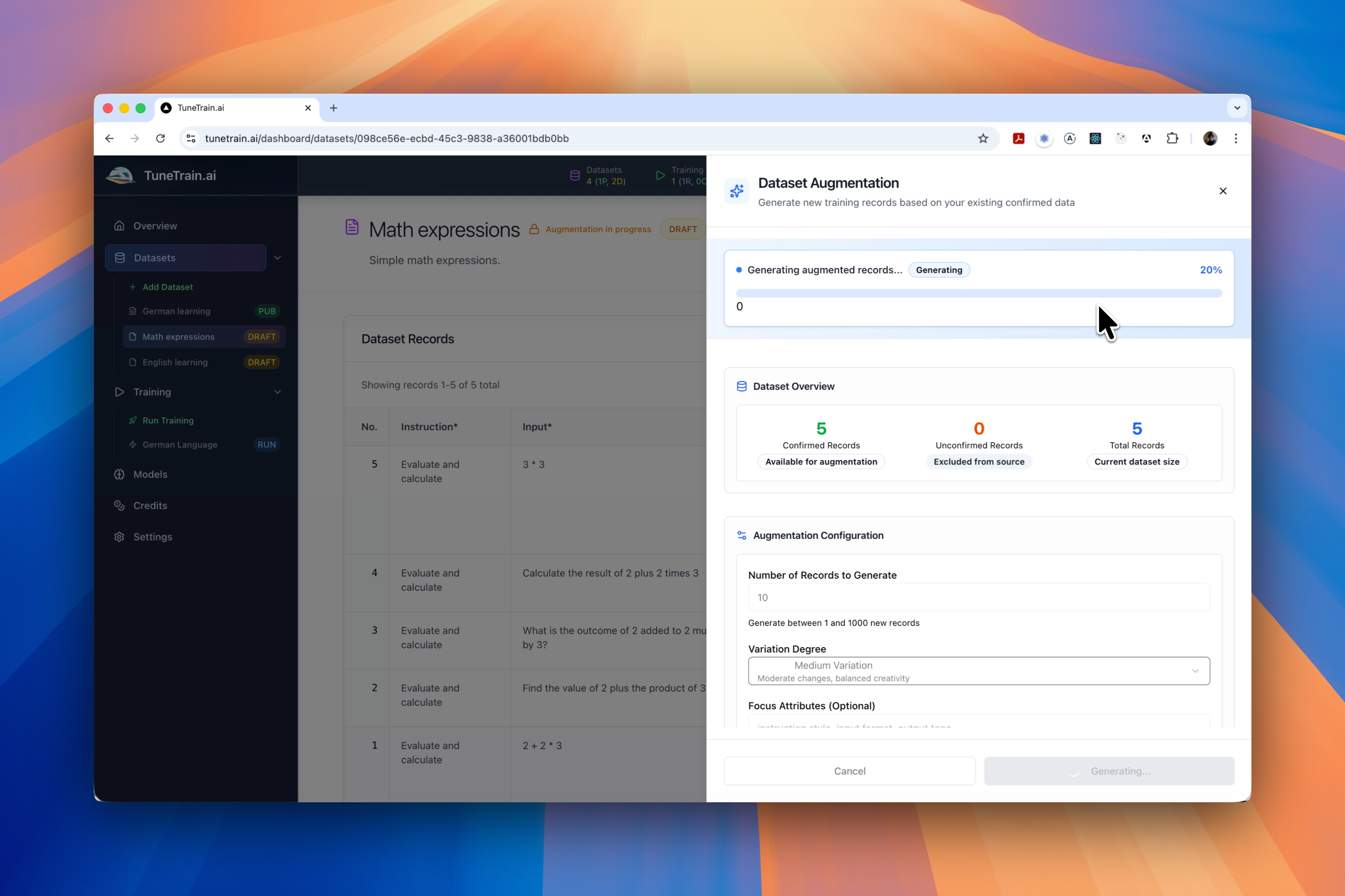
数据集管理与增强
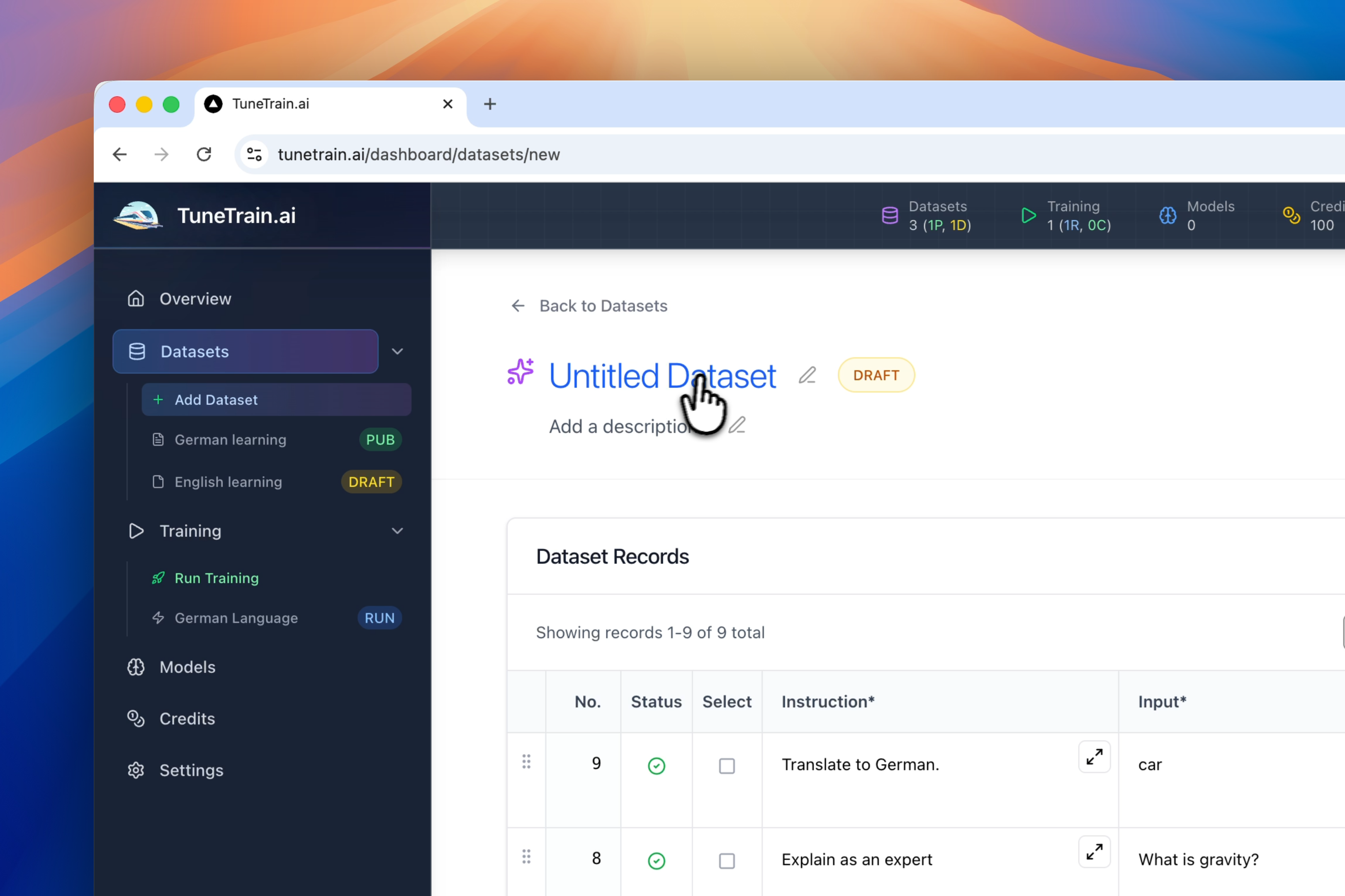
- 灵活上传、高效管理: 支持 CSV 和 JSONL 格式,轻松上传、组织和管理您的数据集。 追踪版本,确保数据质量。
-
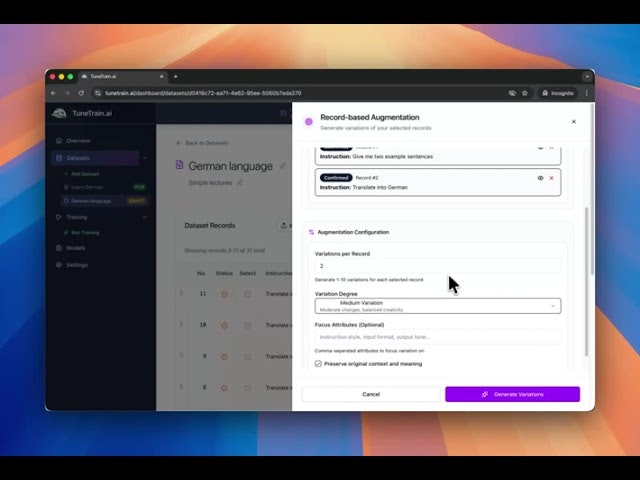
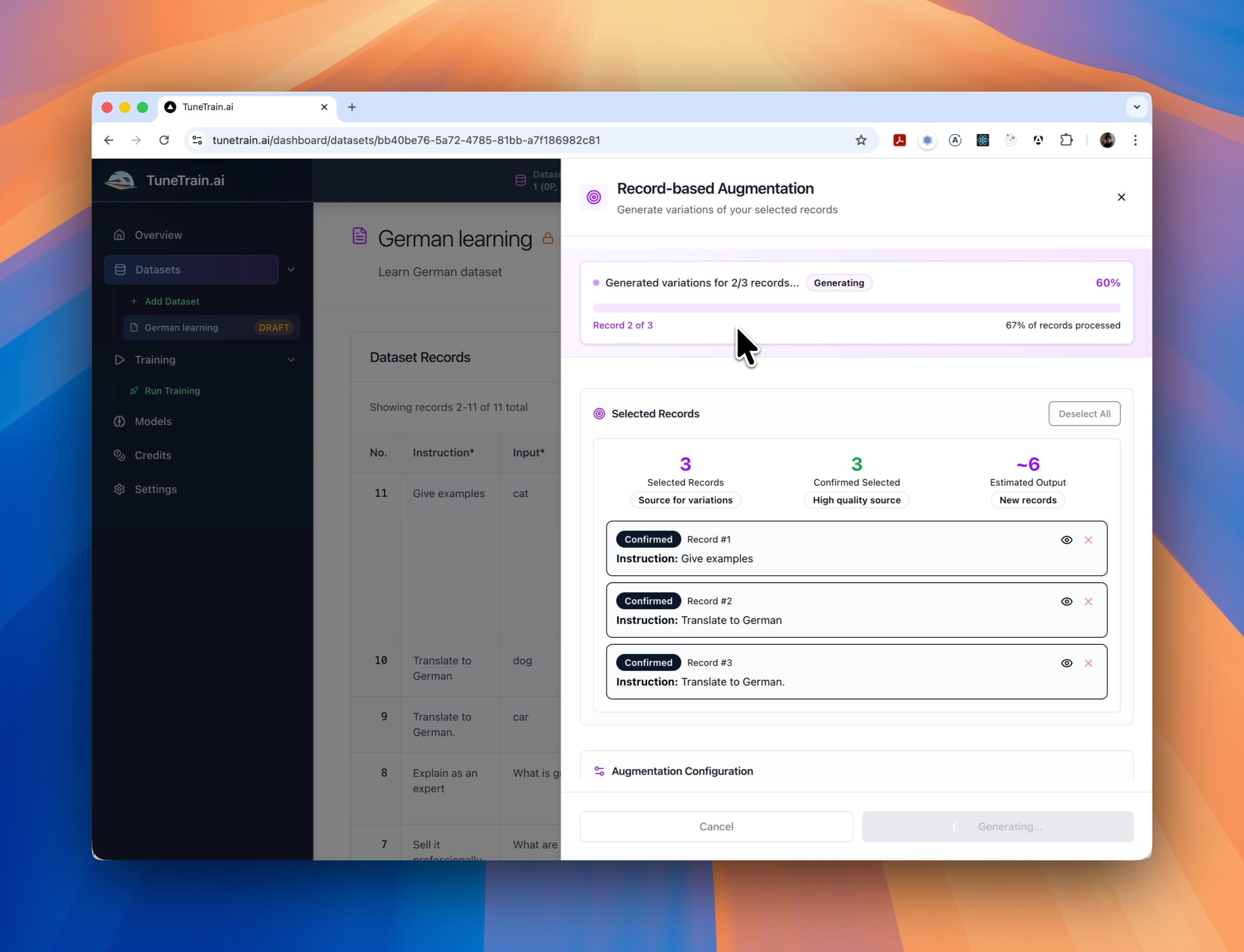
智能数据增强:
生成合成数据变体,自动扩展数据集,提升模型性能和多样性。告别数据量不足的困扰!
- 记录级增强: 基于现有记录,轻松生成新记录,创建多样且全面的数据集,提高模型准确性和鲁棒性。
基于 LLM 的知识蒸馏
我们利用大型语言模型(LLMs)的强大能力,将知识蒸馏到更小、更高效的模型中,同时保持卓越的质量。 这意味着您可以用更低的成本,运行性能同样出色的 AI 模型。
模型定制化
- 指令微调: 训练模型具备指令遵循能力,让 AI 理解并执行特定任务。
- 对话微调(即将推出): 专为聊天机器人和智能助手设计,训练会话式 AI,实现更自然流畅的交互。
模型托管与部署(即将推出)
告别复杂的部署环节!我们将提供托管服务、API 接口和扩展基础设施,让您轻松部署和使用您的微调模型。
❓ 常见问题解答
我需要很多训练数据吗?
不需要!我们的平台可以通过数据集增强功能自动从您的现有记录中生成合成数据变体, 扩展您的数据集并提高多样性。即使训练数据有限,也能帮助您的模型更好地学习模式并进行泛化。
什么是基于 LLM 的蒸馏?
它利用大型语言模型(LLMs)生成高质量示例,优化现有记录,并将知识注入到更小、更高效的模型中。 这使您能够利用先进 LLM 的能力,同时创建运行速度更快、成本效益更高的模型。
TuneTrain.ai 支持哪些模型?
我们支持包括 Llama 3、Mistral、Phi-4、Gemma、Qwen 在内的流行小型语言模型。我们的平台专注于能够在消费级硬件上部署且性能卓越的高效模型。 模型库会定期更新,以包含最新发布。
如何上传数据集?
您可以通过 CSV 和 JSONL 格式上传具有 instruction-input-output 结构的数据集。 我们提供数据集管理工具,用于创建、编辑和组织您的训练数据。
我的数据安全吗?
绝对安全!您的数据在安全环境中加密和处理。我们遵守欧盟 AI 法案,并遵循包括 GDPR 在内的严格数据保护标准。您的数据集和模型对于您的账户而言是私密的, 训练数据绝不会用于改进我们的平台或与第三方共享。
我是否拥有微调模型的版权?
是的,您保留对您微调模型的完整所有权。训练完成后,您可以下载模型文件,包括权重、 配置和分词器。这些模型您可以进行商业用途,不受限制,并且您可以在任何您选择的地方部署它们。
我需要技术背景才能使用 TuneTrain.ai 吗?
不需要技术背景!我们的平台旨在易于使用,提供直观的数据集管理、引导式增强工作流程和自动化训练流程。 当然,理解您的用例和数据结构将有助于获得更好的结果。我们提供全面的指南和最佳实践。
TuneTrain.ai 如何计费?
我们采用基于积分的系统,积分消耗取决于数据集增强和模型训练所使用的计算资源和时间。 您只需为您所使用的服务付费,价格透明且预先可知。每项操作都会在开始前显示其成本, 您可以实时监控您的积分余额。